Named Entity Recognition in Healthcare
Written by Lucas Rosvall, Tech Lead & Co-Founder
The healthcare sector is a treasure trove of data, with daily activities generating vast amounts of information, meticulously stored in Electronic Health Records (EHRs). These records are rich with patient data, including detailed free-text notes by medical professionals.
However, the sheer volume of these records presents a significant challenge: extracting critical information manually from these extensive free-text documents is not just tedious, but practically infeasible.
This is where computational systems come in, processing these large volumes of text automatically.

Named Entity Recognition: A Game Changer in Healthcare
A key technique to tackle this challenge in healthcare lies within the domain of Natural Language Processing (NLP), particularly in Named Entity Recognition (NER).
NER is the process of identifying and categorizing key elements in text, such as names, dates, and other specific data. In the medical field, this could mean pinpointing diseases, pharmaceutical drugs, and personal names in patient records.
Take the following patient record as an example:
“Patient showed good results from the orthopedic clinic, is expected to go home 20230112. Coordinate transport with close relative Anders, tel. 072-124 11 21.”
For this patient note, valuable information for extraction includes the healthcare unit (orthopedic clinic), the date (20230112), a first name (Anders), and a phone number (072-124 11 21).
The process of extracting this information can be performed using several techniques, such as rule- or dictionary-based search systems or by utilizing ML models, such as BERT.
Building a NER system with BERT models
How do you build a system able to extract named entities from texts? One effective approach is utilizing BERT models.
The strength of BERT models in this task lies in their capability to comprehend the context surrounding a word within a sentence, rather than interpreting the word in isolation.
This contextual understanding is crucial for accurately identifying and extracting named entities from texts.
What is BERT?
BERT, short for Bidirectional Encoder Representations from Transformers, represents a major advancement in language processing, introduced by Google in 2018. It's designed to interpret the nuances and complexities of language.
Here's how BERT differs from older models:
- Contextual Understanding: Unlike traditional models that might interpret the word "Apple" only as a fruit, BERT is capable of understanding it in various contexts. Depending on the sentence, BERT can identify "Apple" either as the fruit or as the name of a technology company. This ability to discern the meaning based on context is crucial for accurately identifying and categorizing named entities within texts.
- Bidirectional Analysis: BERT stands out with its ability to analyze text in both directions - left to right and right to left. This bidirectional processing gives BERT a more comprehensive understanding of the sentence structure and meaning, enhancing its capability to recognize and accurately classify named entities within a text.
Below is a visualization of how BERT models can understand that some words relate more to each other than others.

Using Pre-trained BERT models for NER
When developing a Named Entity Recognition (NER) system, there are many pre-trained BERT models available, each trained to understand language in various contexts and specialized domains.
These pre-trained models offer a significant head start, as they have already learned complex language patterns from extensive datasets.
In the healthcare sector, for instance, specific pre-trained BERT models are tailored to understand medical terminology and patient interactions. These models might have been trained on medical journals, patient records, or other healthcare-related texts, making them more adept at recognizing medical entities.
Examples of such models could include BioBERT, which is fine-tuned on biomedical literature, or ClinicalBERT, designed to interpret clinical notes. However, you can also choose to leverage a general-purpose model such as Multilingual BERT.
Leveraging these pre-trained models for NER tasks in healthcare means tapping into their domain-specific language knowledge. This approach not only saves time but often also enhances the accuracy of the model.
Then, by fine-tuning the model with healthcare-specific annotated data, you can further tailor it to identify and classify different entities like diseases, treatments, and medication names more effectively.
Fine-tuning BERT models for NER
Fine-tuning pre-trained BERT models is a crucial step in adapting them for specific tasks, like Named Entity Recognition (NER).
Here's a simpler breakdown of how this process works and how to overcome some common challenges.
What Happens in Fine-Tuning:
BERT models come with a general understanding of language. To make them suitable for specific tasks, like identifying names or medical terms in texts, a special layer – often called a "head" – is added to the model.
This layer is designed to transform BERT's broad language knowledge into something more focused, like recognizing different types of named entities, as shown in the image below.
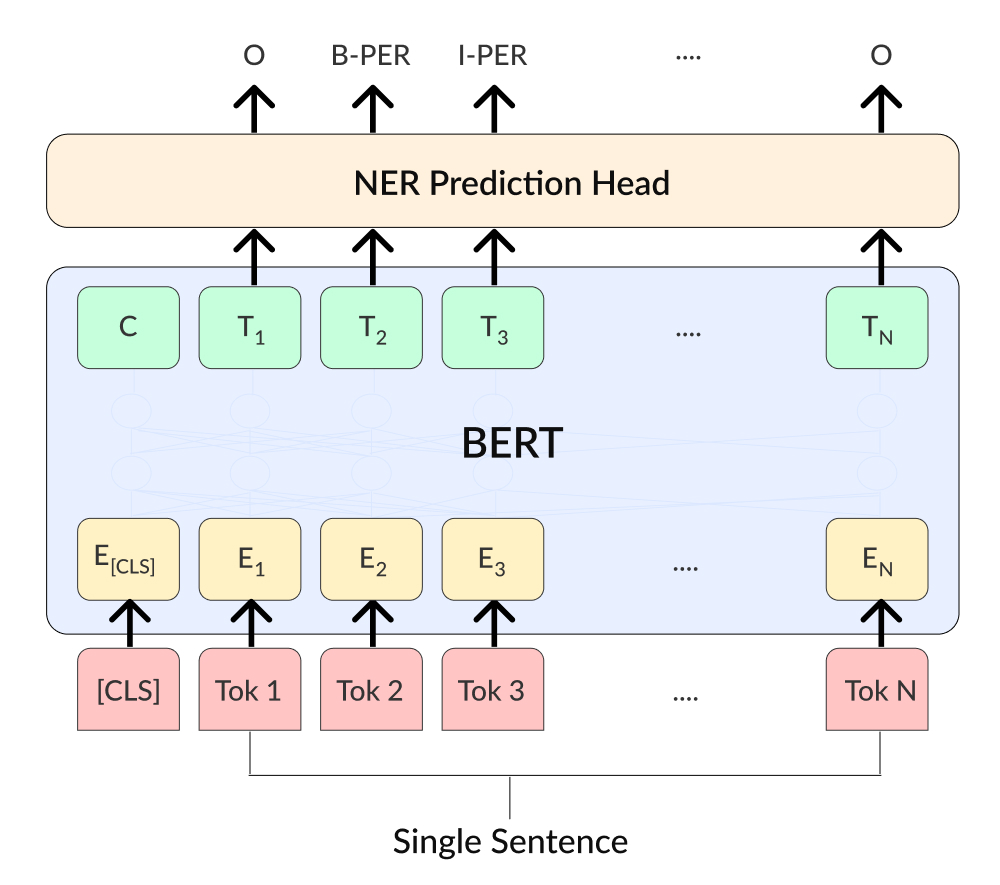
Challenges:
Fine-tuning BERT models can sometimes be tricky. Issues like fine-tuning instability mean that small changes in the process can lead to different results. This is especially true for smaller data sets.
However, there exist approaches to tackle this problem. One solution that we recommend, initially presented by Mosbach et al., is to:
- Fine-tune the BERT model using Adam with bias correction and a learning rate of 2e−5 over 20 epochs.
- Use a learning rate that is linearly increased for the first 10% of steps and linearly decayed to zero afterward.
This method helps the model to learn more effectively, avoiding issues like vanishing gradients (where the model stops learning) or inconsistencies late in the training.
How NER could improve healthcare
Named Entity Recognition (NER) in healthcare isn't just about organizing data; it also supports patient care and medical research.
By extracting specific entities from vast amounts of unstructured data in medical records, NER can streamline clinical processes and open new avenues for medical research.
The immediate benefit of NER in healthcare is its ability to swiftly sift through and organize critical patient information such as symptoms, diagnoses, medications, and patient histories. This efficiency not only saves time but also brings a new level of precision to patient care.
Moreover, NER systems can substantially reduce the administrative burden on healthcare professionals.
Beyond individual patient care, the information extracted by NER systems can be a goldmine for other machine learning (ML) tasks.
Aggregated data on diseases, treatments, outcomes, and patient demographics can be anonymized and analyzed to uncover trends and patterns that would be impossible to discern from individual records.
This analysis could for example lead to predictive models for disease outbreaks, more effective public health strategies, and even insights into the efficacy of certain treatments across different demographics.
Of course, with the immense potential of NER comes the responsibility of handling sensitive patient data. Ensuring that all extracted data is anonymized or pseudonymized is paramount to maintain patient confidentiality and comply with privacy regulations.
However, if we navigate these challenges and use NER responsibly, healthcare providers can extract far more value from the records they already hold. By efficiently leveraging anonymized data, NER systems can help connect information across records that would otherwise stay siloed.