Data augmentation for NER using Back Translation
Written by Lucas Rosvall, Tech Lead & Co-Founder
In our latest post, we talked about Named Entity Recognition (NER) in Healthcare, which is the process of identifying and categorizing key elements in text, such as names, dates, and other specific data.
In this article, we will delve deeper into the challenges and solutions associated with NER, particularly focusing on innovative data augmentation techniques like back translation for enhancing our NER systems.
Data Augmentation for NER
Data augmentation is a crucial technique in training deep learning models, prominently utilized across various domains. In computer vision, standard practices like rotation, cropping, and masking effectively increase the dataset by generating new image variations.
For language, however, small adjustments to the sentence can completely change its meaning. For NLP applications and NER in particular, great care needs to be applied to not accidentally distort texts to a degree where the labels are lost or represent the wrong entity.
There also exist different techniques for performing data augmentation in NLP and NER:
- Character-level augmentation: Makes small modifications on a character level. For example, by using different character-level augmentation techniques, the word “telephone” could be transformed into “telephon” by removing a character, or into “telehone” by inserting a character.
- Token-level augmentation: Manipulates words and phrases within a sentence to generate new synthetic texts. For instance, it can be achieved by substituting a word with its synonym or eliminating a random word from the sentence, thereby creating a novel but contextually similar text.
- Sentence-level augmentation: Changes the text on a sentence-level by altering the structure or rearranging the content in sentences to generate new sentences and contexts. For example, a paragraph could be divided into individual sentences or clauses, which are then shuffled and reassembled in a different order.
What is Back Translation?
Back translation is a data augmentation technique that has proven to be quite effective in NLP. It involves a two-step translation process: first, you translate a sentence from its original language to a different language, and then you translate it back to the original language.
There is also a unique aspect of back translation compared to other data augmentation methods. While other techniques often rely on either augmentation on the token level or the sentence level, back translation can be used to introduce changes on both levels.
Furthermore, back translation also maintains the essential context and meaning of the text very well. This is particularly important in NER, where the context of the text is crucial for the correct identification of named entities.
But how can you perform back translation?
Back translation can be performed using a couple of different tools. For instance, 'MarianMT', a state-of-the-art neural machine translation model, is frequently used for its efficiency and accuracy in translating between multiple languages.
Alternatively, the 'Google Translate API' offers a widely accessible and versatile option, capable of handling a vast array of languages and dialects.
Challenges and Solutions for Back Translation in NER
When using machine translation for NER, translating full sentences without guidelines can be tricky. This is because changing words or sentence structures might mess up important info about named entities and their context.
For this problem, we have explored two solutions specifically for NER translation, which we call word-for-word and sense-for-sense translation. Both of these methods ensure key information such as labels and named entities stay the same.
Word-for-word translation
The most simple method when translating text for the purpose of data augmentation in NER is referred to as word-for-word (w4w) translation. Here each word is translated separately into the target language and back again.
This means that the words are translated one by one in the order as they appear in the source text, without regard for the complete sentence’s context or grammar. As a result, this method doesn’t alter the order of the entity labels in the sentence.
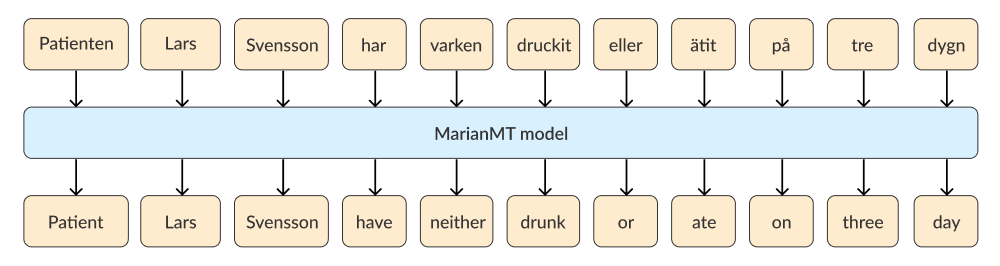
Although the w4w translation can be helpful because of its simplicity, it ignores the relationship between words. Subsequently, the produced translations tend to sound awkward and often include grammatical errors in the target language, as seen in the image above.
Sense-for-sense translation
The second approach, sense-for-sense translation, that we have developed especially for NER is aimed to keep a text’s original meaning or sense as best as possible when translated into the target language.
For this method, the entities are masked to save their position. This is done by replacing entities with a text string of the format X-[document index]-[token index in document], e.g., X12-1. The back-translation can then be performed using a language model, such as MarianMT or the Google Translate API.
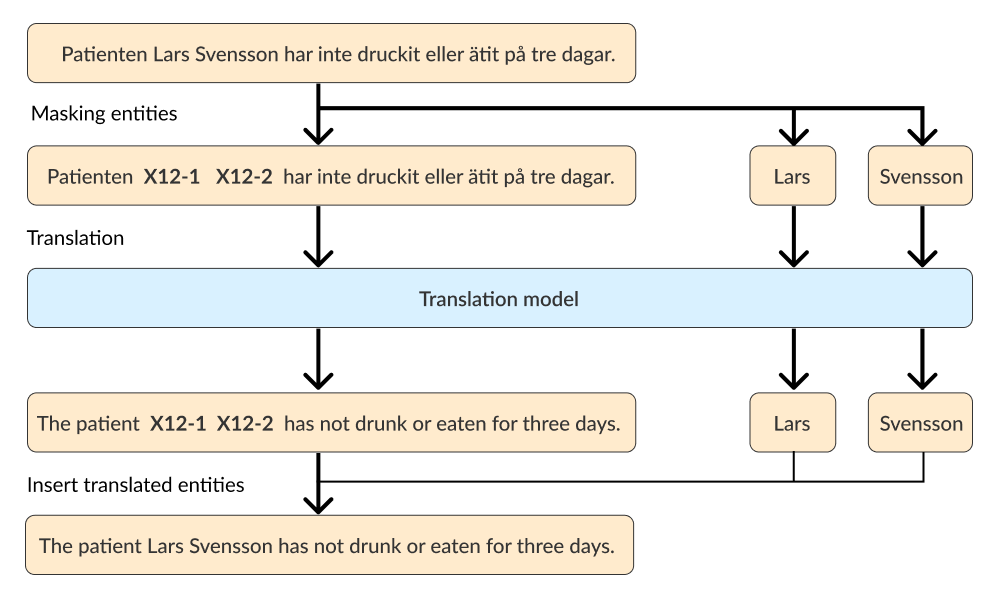
The process is as follows: by applying masks in this specific format, the translation model is instructed to bypass the masked tokens while translating the rest of the document.
After the initial translation, these masked tokens are then translated separately using the same translation model. Finally, these separately translated tokens are reinserted into the text, ensuring the preservation of the original sense while maintaining accurate translation.